论文笔记4 - Flamingo
Flamingo: a Visual Language Model for Few-Shot Learning
概述
- 最先进的few-shot视觉问答注意力网络,接受灵活的图像/文本输入
- 利用cross attention实现图像压缩与图文信息交互
- 通过设置prompt,大模型+少样本打败精调。

模型结构
怎样将图像和文本一起输入LLM?
将图像数据从2D转化为1D,以输入Transformer,作者除采用ViT中常见的patch_embedding(一个预训练的Resnet)外,还用一个Transformer模块对image patch的token数量进行了压缩。
压缩的方法就是引入一个Perceiver Resampler模块,核心是做attention,如下图所示,用R个可学习的token作为Query,图像编码\(X_f\)和R个token的拼接作为K和V(拼接后效果略好),这样attention下来输出也是R个token,从而将图像token数量压缩到R个。
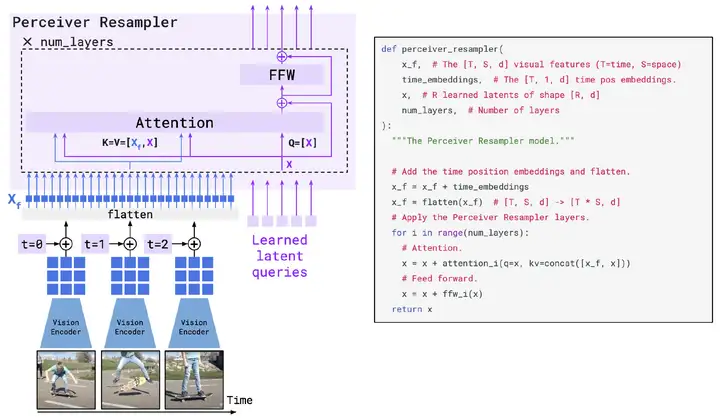
如何利用预训练的LLM?
作者从一个预训练好的70B语言模型Chinchilla开始加入图像信息,考虑到保留之前LM学到的知识,训练时需要把LM的参数冻住,因此提出了Gated Cross attention机制来融合图像和文本。
具体来说,还是利用attention机制,如下图所示,把文本编码当作Q,图像编码当作K和V,这样输出的维度还是跟之前文本的一样。之后还是正常过FFW。同时为了提升稳定性和效果,在attention和FFW之后都增加了tanh门控,先开始是0,之后逐步增加。
这个过程可以理解为以文本输入为载体,将图像信息嵌入到文本信息之中
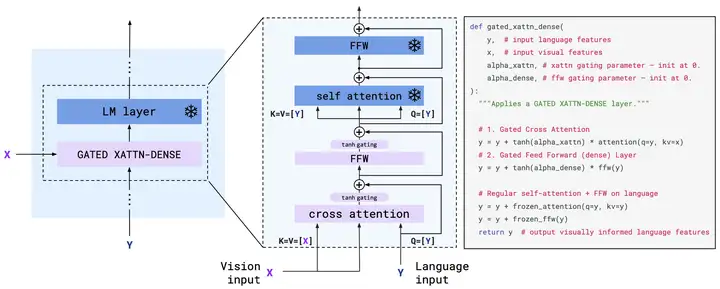
但为了减少参数量,这个机制不一定每层都有(但每层都添加效果更好),具体增加的策略如下:

同时为了减少不相关的图像噪声,提高训练的稳定性,增加mask策略使得在cross-attention时每段文字只能关注到它之前的一个图像。
但cross-attention之后的self-attention还是保持LM的causal attention,可以保证在预测输出时会关注到以前所有的文字和图像。
如何构造训练数据?
需要的训练数据为图像文本对,在大量网页上爬取得到M3W数据集。