论文笔记2 - ONE-PEACE
ONE-PEACE: EXPLORING ONE GENERAL REPRESENTATION MODEL TOWARD UNLIMITED MODALITIES
概述
一种多模态预训练方法,可扩展至无限种模态,在不使用任何视觉或语言预训练模型进行初始化的情况下,ONE-PEACE在广泛的单模态和多模态任务中取得了领先的结果。
ONE-PEACE实际训练了图像、文本、语音三个模态,其中文本为中心模态,以对齐其他两个模态。
模型结构
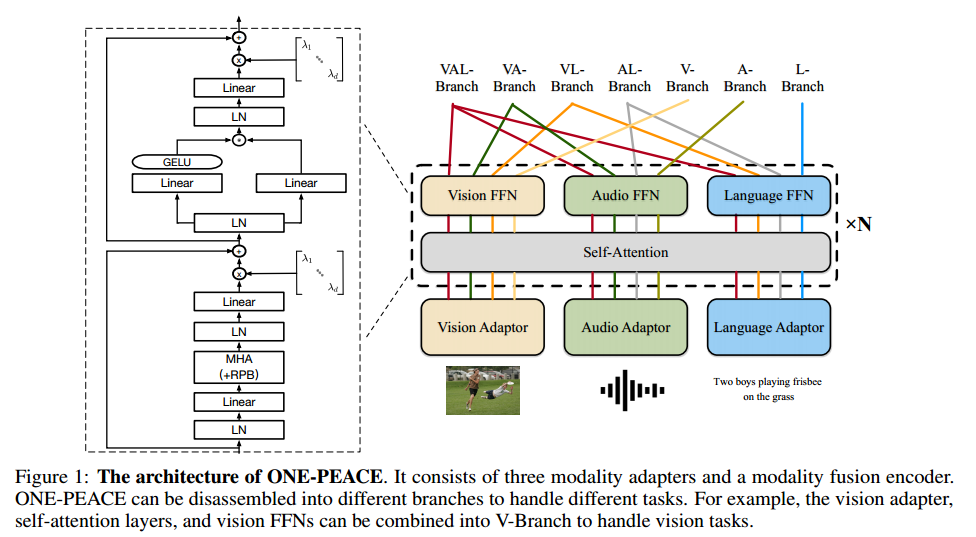
Modality Adapters(对应ViT中的patch_embed层)
Vision Adapter:使用分层MLP(hMLP,来源)改进patch_embed层以更好地适应MIM,hMLP等价于三个卷积层(4x4 conv -> 2x2 conv -> 2x2 conv)级联,不同patch之间没有信息交互,和原生ViT的处理(一个stride=16且kernel_size=16的卷积层)兼容。

Audio Adapter:
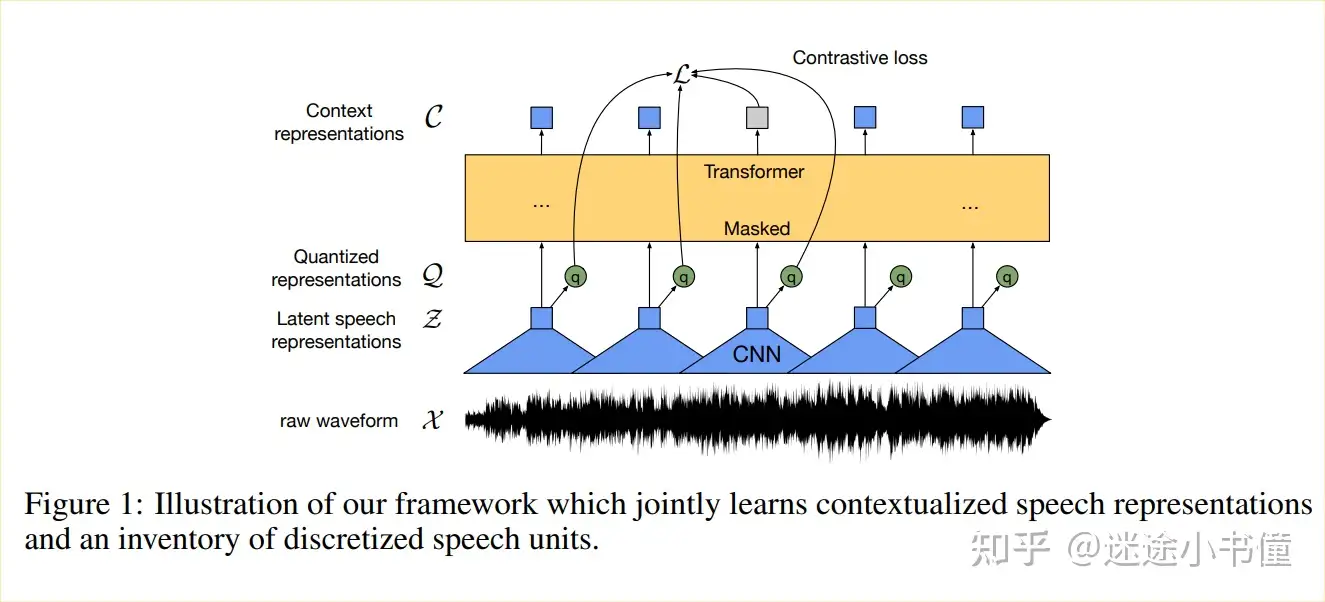
使用wav2vec 2.0中的CNN特征提取器得到audio embeddings。wav2vec 2.0是音频自监督表征学习的经典方法,其使用Z(audio embeddings)”量化“得到的Q,与对Z mask+transformer得到的C进行对比学习,从而达到预训练的目的。
这里的”量化“不同于模型压缩中的量化,而是”乘积量化“,意思是指把原来的向量空间分解为若干个低维向量空间的笛卡尔积,并对分解得到的低维向量空间分别做量化,从而把连续空间量化成有限空间。具体为把原来连续的特征空间假设是d维,拆分成G个子空间(codebook),每个子空间维度是d/G。然后分别在每个子空间里面聚类(K-mean什么的),一共获得V个中心和其中心特征。每个类别的特征用其中心特征代替。
结果就是,原来d维的连续空间(有无限种特征表达形式),坍缩成了有限离线的空间[GxV],其可能的特征种类数就只有G*V个。
乘积量化巧妙在哪儿:
乘积量化操作通过将无限的特征表达空间坍缩成有限的离散空间,让特征的鲁棒性更强,不会受少量扰动的影响(只要还在某一类里面,特征都由中心特征来代替)。这个聚类过程也是一个特征提取的过程,让特征的表征能力更强了。
VQVAE中也有类似的量化操作
Audio Adapter没有使用绝对位置嵌入,而是使用卷积层提取相对位置信息并将其添加到音频嵌入中。
1
2
3x_conv = self.pos_conv(x.transpose(1, 2))
x_conv = x_conv.transpose(1, 2)
x = x + x_conv1
2
3
4
5
6(encoder): TransformerEncoder(
(pos_conv): Sequential(
(0): Conv1d(768, 768, kernel_size=(128,), stride=(1,), padding=(64,), groups=16)
(1): SamePad()
(2): GELU(approximate=none)
)
Language Adapter:常规,BPE -> add CLS/EOS token -> embedding layer
Modality Fusion Encoder:每个Transformer层中包含一个共享自注意力层和三个模态前馈网络(ffn),改进点:
Sub-LayerNorm
GeGLU Activation Function:FFN的中间维数设置为嵌入维数的4倍,这与PaLM的做法一致
Relative Position Bias (RPB,相对位置偏差):添加到自注意力层中的q@k.T中,文本和音频引入1D RPB,图像引入2D RPB。在预训练阶段,不同自注意层的相对位置偏差是共享的。在微调阶段,解耦每个自注意层的相对位置偏差,并让它们继承预训练的相对偏差的权重。
EVA02代码中有RPB的代码实现
LayerScale:在加入残差之前,我们将每一层(attn层和FFN层)的输出乘以一个可学习的对角矩阵。
预训练任务
跨模态对比学习:与CLIP相同
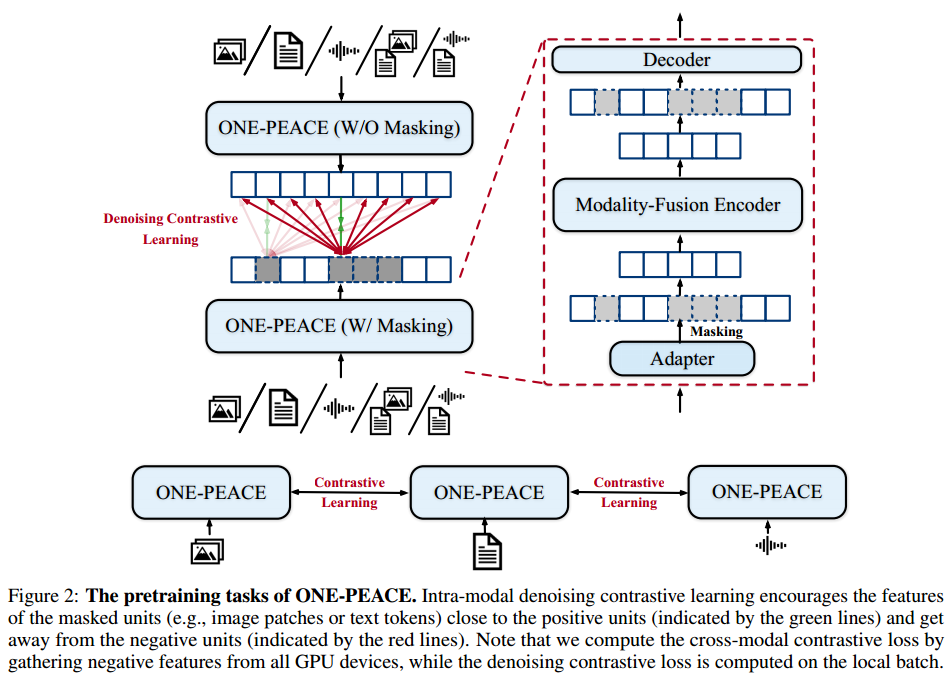
模态内去噪对比学习:
掩模预测和对比学习的结合,在细粒度掩模特征和可见特征(如图像patch、文本token或音频波形特征)之间执行对比损失。
引入该任务原因:跨模态对比学习主要关注不同模态的对齐,缺乏对模态内细粒度细节学习的重视,导致下游任务的性能不佳。
模态内去噪对比学习应用于5种类型的数据:图像、音频、文本、图像-文本对和音频-文本对。
训练加速/内存优化策略
- xformers库: memory-efficient attention
- checkpoint机制:节省内存,以更大的batchsize训练模型
- Flash Attention库:Fused LayerNorm
- nvFuser:融合dropout、LayerScale、随机深度和残差和操作,可以带来额外的速度提升
- float16精度训练