论文笔记1 - VLMo
VLMo: Unified Vision-Language Pre-Training with Mixture-of-Modality-Experts
概述
- 一种图文多模态预训练方法,经过预训练的VLMO可作为视觉语言分类任务(Vision-Language Classification )的融合编码器或图像文本检索(Vision-Language Retrieval)的双重编码器进行微调。
训练策略
以往的两种主流图文预训练架构:
①对比学习:双编码器,计算图像和文本的相似度,这种方法对检索任务非常有效,但图像和文本之间简单的浅层交互不足以处理复杂的VL分类任务。(CLIP特征的局限性,DALL·E 2论文中也提到了这个问题)
②融合编码器(fusion encoder):联合编码所有可能的图像-文本对,以计算检索任务的相似性得分。在VL分类任务中表现出色,但计算量大。
VLMo模型是这两种预训练策略的结合。
预训练
预训练过程分为三阶段,图文数据共享attention层,通过添加不同的type_embedding区分数据类型。
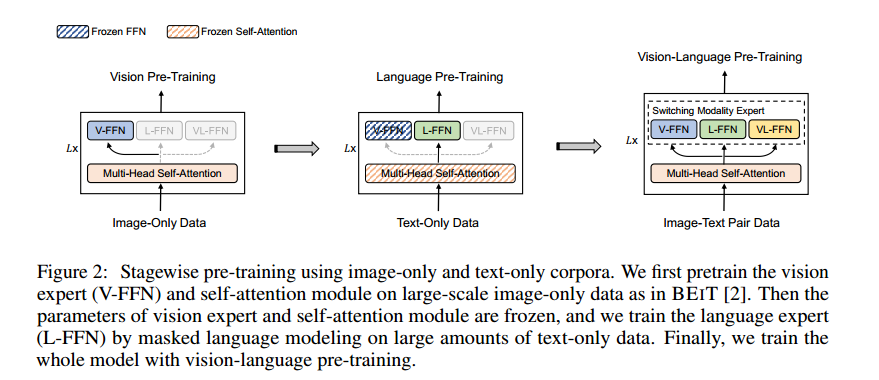
纯图训练,采用beit提出的MIM方法对attention部分和V-FFN部分训练
纯文本训练,冻结attention和V-FFN的参数,掩码文本训练L-FFN
图像-文本对训练,开放调整所有参数,使用Image-Text Contrast、Masked Language Modeling和Image-Text Matching三个任务进行训练
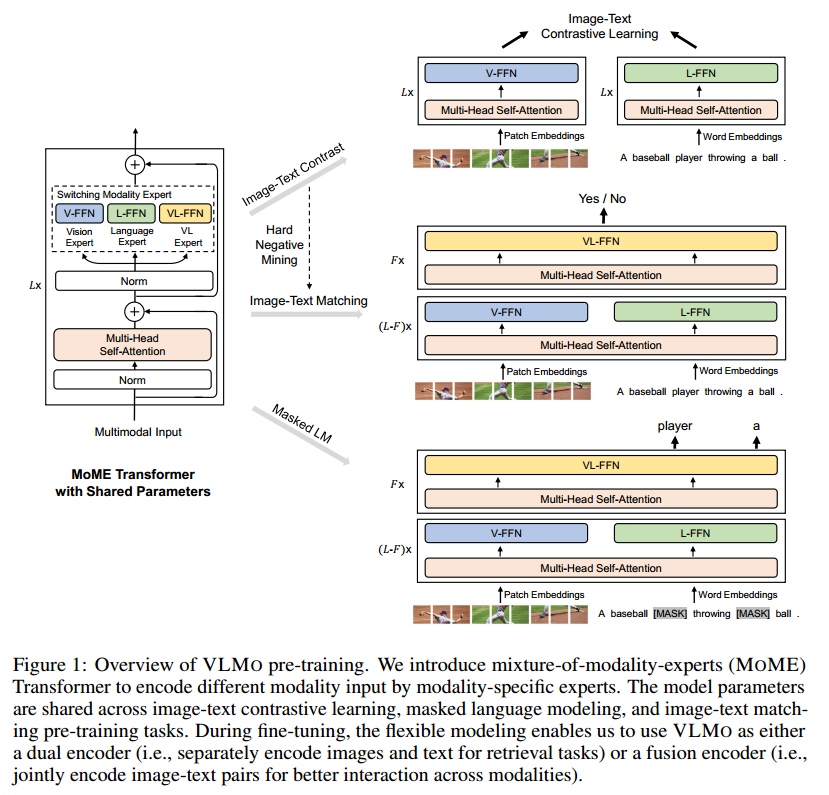
优点:除了图像-文本对之外,还有效地利用了大规模纯图像和纯文本数据。在大量纯图像和纯文本数据上进行分阶段预训练有助于VLMO学习更多通用表征。
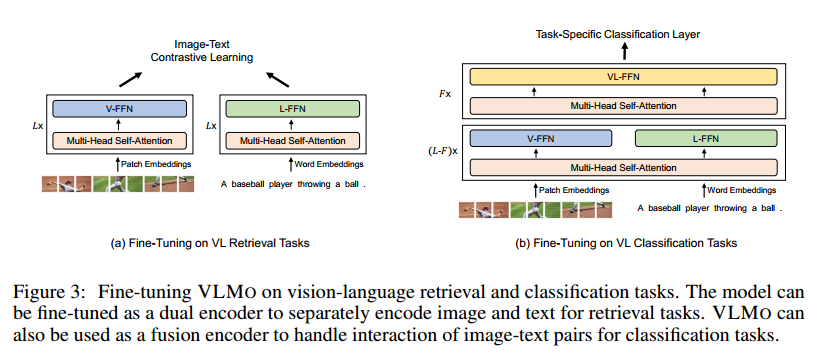
微调
- 视觉语言检索,用作双编码器
- 视觉语言分类,用作融合编码器
论文笔记1 - VLMo
https://robert-zwr.github.io/2023/07/12/论文笔记1-VLMo/